Showing posts with label SQL. Show all posts
Showing posts with label SQL. Show all posts
Monday, October 22, 2012
Flattening an XML Structure for MySQL Import
Recently a buddy asked me to help him convert BuddyPress XML data into a MySQL database. There are several software options that will import XML into MySQL or other databases, but they don't handle fields past the second level. So this project posed two challenges. First, the BuddyPress data is only available in single day increments in XML files. So you have to download an XML for every day for every table. That is a lot of files. The second challenge is that all of that XML data needed to be merged into a single file, with all of the fields flattened to a single level, while maintaining their identity.
To solve problem #1, I wrote a PowerShell script that would use dates and an array of table names to do a series of loops. This allowed the automatic generation of a URL for each day for each table. That URL was passed to the following function, which would download the XML file. Since each URL was limited to 1000 records, it was actually possible that a table could have more than one XML file for each day, so I added some logic to check the XML file to see if there was another page of records, and to call its self against that next page if it existed.
$global:wc=new-object system.net.webclient
function download-xml {
param ($url, $file)
write-host Downloading $file
$global:wc.downloadfile($url,$file)
[xml]$xml = get-content $file
if ($xml.ContentEnvelope.ContentHeader.NextPageUrl) {
$nextFile = $file + "_" + $xml.ContentEnvelope.ContentHeader.CurrentPage
download-xml $xml.ContentEnvelope.ContentHeader.NextPageUrl $nextFile
}
}
That script worked great, and netted me about 3900 XML files, each with up to 1000 records. To get them into MySQL, I needed each tables XML file combined into a single file. That part is pretty easy, but while combining them, I also needed to flatten all of the fields into the second level. That meant turning this:
<BlogPost>
<NeedsToUpdateFullText>True</NeedsToUpdateFullText>
<SkipLists>False</SkipLists>
<UpdatingComments>False</UpdatingComments>
<Title>Some Blog Title</Title>
<UnencodedTitle>Some Blog Title</UnencodedTitle>
<Body><p>Lots of blog content :)</p></Body>
<Tags />
<TagsPrevious />
<TimeStamp>2012-07-08T08:17:00-07:00</TimeStamp>
<IsPublished>True</IsPublished>
<ParentKey>
<UserKey>
<IsAnonymous>False</IsAnonymous>
<DontParseKeySeed>False</DontParseKeySeed>
<Key>2bda27f7-cb12-4e5c-949c-c4c36757a626</Key>
<ObjectType>Models.Users.UserKey</ObjectType>
<PartitionHash>
<Byte>131</Byte>
<Byte>4</Byte>
</PartitionHash>
</UserKey>
<DontParseKeySeed>False</DontParseKeySeed>
<Key>Blog:2bda27f7-cb12-4e5c-949c-c4c36757a626</Key>
<ObjectType>Models.Blogs.BlogKey</ObjectType>
<PartitionHash>
<Byte>150</Byte>
<Byte>135</Byte>
</PartitionHash>
</ParentKey>
<LastEditedBy>
<IsAnonymous>False</IsAnonymous>
<DontParseKeySeed>False</DontParseKeySeed>
<Key>2bda27f7-cb12-4e5c-949c-c4c36757a626</Key>
<ObjectType>Models.Users.UserKey</ObjectType>
<PartitionHash>
<Byte>131</Byte>
<Byte>4</Byte>
</PartitionHash>
</LastEditedBy>
<LastEditTimeStamp>2012-07-08T08:17:00-07:00</LastEditTimeStamp>
<LastCommentDate>0001-01-01T00:00:00-08:00</LastCommentDate>
<Key>
<BlogKey>
<UserKey>
<IsAnonymous>False</IsAnonymous>
<DontParseKeySeed>False</DontParseKeySeed>
<Key>2bda27f7-cb12-4e5c-949c-c4c36757a626</Key>
<ObjectType>Models.Users.UserKey</ObjectType>
<PartitionHash>
<Byte>131</Byte>
<Byte>4</Byte>
</PartitionHash>
</UserKey>
<DontParseKeySeed>False</DontParseKeySeed>
<Key>Blog:2bda27f7-cb12-4e5c-949c-c4c36757a626</Key>
<ObjectType>Models.Blogs.BlogKey</ObjectType>
<PartitionHash>
<Byte>150</Byte>
<Byte>135</Byte>
</PartitionHash>
</BlogKey>
<DontParseKeySeed>False</DontParseKeySeed>
<Key>Blog:2bda27f7-cb12-4e5c-949c-c4c36757a626Post:f23c33f7-932c-46d4-9dc6-7b44a4a95328</Key>
<ObjectType>Models.Blogs.BlogPostKey</ObjectType>
<PartitionHash>
<Byte>55</Byte>
<Byte>64</Byte>
</PartitionHash>
</Key>
<ContentBlockingState>Unblocked</ContentBlockingState>
<ImmuneToAbuseReportsState>NotImmune</ImmuneToAbuseReportsState>
<Owner>
<IsAnonymous>False</IsAnonymous>
<DontParseKeySeed>False</DontParseKeySeed>
<Key>2bda27f7-cb12-4e5c-949c-c4c36757a626</Key>
<ObjectType>Models.Users.UserKey</ObjectType>
<PartitionHash>
<Byte>131</Byte>
<Byte>4</Byte>
</PartitionHash>
</Owner>
<LastUpdated>2012-07-08T08:12:27-07:00</LastUpdated>
<CreatedOn>2012-07-08T08:12:27-07:00</CreatedOn>
<SiteOfOriginKey>system</SiteOfOriginKey>
</BlogPost>
Into this:
<BlogPost>
<NeedsToUpdateFullText>True</NeedsToUpdateFullText>
<SkipLists>False</SkipLists>
<UpdatingComments>False</UpdatingComments>
<Title>Some Blog Title</Title>
<UnencodedTitle>Some Blog Title</UnencodedTitle>
<Body><p>Lots of blog content :)</p></Body>
<Tags></Tags>
<TagsPrevious></TagsPrevious>
<BodyAbstract></BodyAbstract>
<ContentBlockingState>Unblocked</ContentBlockingState>
<CreatedOn>2012-06-19 10:15:50-07:00</CreatedOn>
<ImmuneToAbuseReportsState>NotImmune</ImmuneToAbuseReportsState>
<IsPublished>True</IsPublished>
<Key_BlogKey_DontParseKeySeed>False</Key_BlogKey_DontParseKeySeed>
<Key_BlogKey_Key>Blog:a3f689bc-f77c-4f5b-a358-9197a7c7c246@D|9;36|CommGroup5897d62d-6f6e-41fd-8cce-5c8d288dab3d|</Key_BlogKey_Key>
<Key_BlogKey_ObjectType>Models.Blogs.BlogKey</Key_BlogKey_ObjectType>
<Key_BlogKey_PartitionHash_Byte1>90</Key_BlogKey_PartitionHash_Byte1>
<Key_BlogKey_PartitionHash_Byte2>131</Key_BlogKey_PartitionHash_Byte2>
<Key_BlogKey_UserKey_DontParseKeySeed>False</Key_BlogKey_UserKey_DontParseKeySeed>
<Key_BlogKey_UserKey_IsAnonymous>False</Key_BlogKey_UserKey_IsAnonymous>
<Key_BlogKey_UserKey_Key>a3f689bc-f77c-4f5b-a358-9197a7c7c246@d|9;36|commgroup5897d62d-6f6e-41fd-8cce-5c8d288dab3d|</Key_BlogKey_UserKey_Key>
<Key_BlogKey_UserKey_ObjectType>Models.Users.UserKey</Key_BlogKey_UserKey_ObjectType>
<Key_BlogKey_UserKey_PartitionHash_Byte1>108</Key_BlogKey_UserKey_PartitionHash_Byte1>
<Key_BlogKey_UserKey_PartitionHash_Byte2>104</Key_BlogKey_UserKey_PartitionHash_Byte2>
<Key_DontParseKeySeed>False</Key_DontParseKeySeed>
<Key_Key>Blog:a3f689bc-f77c-4f5b-a358-9197a7c7c246@D|9;36|CommGroup5897d62d-6f6e-41fd-8cce-5c8d288dab3d|Post:7147d535-9a47-4987-a9c6-9c695f0c8a6c</Key_Key>
<Key_ObjectType>Models.Blogs.BlogPostKey</Key_ObjectType>
<Key_PartitionHash_Byte1>156</Key_PartitionHash_Byte1>
<Key_PartitionHash_Byte2>175</Key_PartitionHash_Byte2>
<LastCommentDate>0001-01-01T00:00:00-08:00</LastCommentDate>
<LastEditedBy_DontParseKeySeed>False</LastEditedBy_DontParseKeySeed>
<LastEditedBy_IsAnonymous>False</LastEditedBy_IsAnonymous>
<LastEditedBy_Key>511bcfae-b9f6-4831-a81b-2a0c76529c06</LastEditedBy_Key>
<LastEditedBy_ObjectType>Models.Users.UserKey</LastEditedBy_ObjectType>
<LastEditedBy_PartitionHash_Byte1>41</LastEditedBy_PartitionHash_Byte1>
<LastEditedBy_PartitionHash_Byte2>127</LastEditedBy_PartitionHash_Byte2>
<LastEditTimeStamp>2012-03-26 10:18:46-07:00</LastEditTimeStamp>
<LastUpdated>2012-06-19 10:15:50-07:00</LastUpdated>
<NeedsToUpdateFullText>True</NeedsToUpdateFullText>
<Owner_DontParseKeySeed>False</Owner_DontParseKeySeed>
<Owner_IsAnonymous>False</Owner_IsAnonymous>
<Owner_Key>511bcfae-b9f6-4831-a81b-2a0c76529c06</Owner_Key>
<Owner_ObjectType>Models.Users.UserKey</Owner_ObjectType>
<Owner_PartitionHash_Byte1>41</Owner_PartitionHash_Byte1>
<Owner_PartitionHash_Byte2>127</Owner_PartitionHash_Byte2>
<ParentKey_DontParseKeySeed>False</ParentKey_DontParseKeySeed>
<ParentKey_Key>Blog:a3f689bc-f77c-4f5b-a358-9197a7c7c246@D|9;36|CommGroup5897d62d-6f6e-41fd-8cce-5c8d288dab3d|</ParentKey_Key>
<ParentKey_ObjectType>Models.Blogs.BlogKey</ParentKey_ObjectType>
<ParentKey_PartitionHash_Byte1>90</ParentKey_PartitionHash_Byte1>
<ParentKey_PartitionHash_Byte2>131</ParentKey_PartitionHash_Byte2>
<ParentKey_UserKey_DontParseKeySeed>False</ParentKey_UserKey_DontParseKeySeed>
<ParentKey_UserKey_IsAnonymous>False</ParentKey_UserKey_IsAnonymous>
<ParentKey_UserKey_Key>a3f689bc-f77c-4f5b-a358-9197a7c7c246@d|9;36|commgroup5897d62d-6f6e-41fd-8cce-5c8d288dab3d|</ParentKey_UserKey_Key>
<ParentKey_UserKey_ObjectType>Models.Users.UserKey</ParentKey_UserKey_ObjectType>
<ParentKey_UserKey_PartitionHash_Byte1>108</ParentKey_UserKey_PartitionHash_Byte1>
<ParentKey_UserKey_PartitionHash_Byte2>104</ParentKey_UserKey_PartitionHash_Byte2>
<SiteOfOriginKey>system</SiteOfOriginKey>
<SkipLists>False</SkipLists>
<Tags>Nursing</Tags>
<TagsPrevious>Nursing</TagsPrevious>
<TimeStamp>2012-03-26 10:18:46-07:00</TimeStamp>
<Title>Keep Trying!</Title>
<UnencodedTitle>Keep Trying!</UnencodedTitle>
<UpdatingComments>False</UpdatingComments>
</BlogPost>
Since PowerShell handles XML natively, it seemed like the perfect tool. Since I didn't want to build a custom script for each XML file, I needed the script to be agnostic to the XML fields. To accomplish that, I had the script import an XML file, loop through each property in the XML file and check the property type. If the property type is "XmlElement", the script knows it has child items and starts looping through those properties. If the type isn't "XmlElement", it knows that it has a field and writes the output to an XML file. Because each table potentially has thousands of rows, the file write is done with the .NET [System.IO.StreamWriter], which is by far the fastest way to write a file from PowerShell. Placing the XML flattening process into a function allowed me to easily loop through all of the files for a specific table, and all of the records in each file. In order to maintain the integrity of the XML paths, I pass the parent path to the function. That way we don't end up with multiple "Key" fields at the root, but instead have fields named with the full XML path of the item moved to the root. For example, this path:
<ParentKey>
<UserKey>
<IsAnonymous>False</IsAnonymous>
becomes this:
<ParentKey_UserKey_IsAnonymous>False</ParentKey_UserKey_IsAnonymous>
Here is the flatten-xml function that accomplished that:
$stream = [System.IO.StreamWriter] "C:\BlogPost.xml"
function global:flatten-field {
param (
$parent,
$element,
$fieldname
)
if ($parent -eq "") {
$label = $fieldname
} else {
$label = $parent + "_" + $fieldname
}
if ((($element.GetType()).Name) -eq "XmlElement") {
$element | get-member | where-object { $_.MemberType -eq "Property" } | % {
global:flatten-field $label $element.($_.Name) $_.Name
}
} else {
if (($element.length -eq 25) -and ($element -like "2012-*")) { $element = $element.replace("T"," ") }
if ($fieldname -eq "Byte") {
$row = "`t<" + $label + "1>" + $element[0] + "</" + $label + "1>" + "<" + $label + "2>" + $element[1] + "</" + $label + "2>"
} else {
$element = $element.replace("&","&")
$element = $element.replace("'","'")
$element = $element.replace('"',""")
$element = $element.replace("<","<")
$element = $element.replace(">",">")
$row = "`t<" + $label + ">" + $element + "</" + $label + ">"
}
$stream.WriteLine($row)
}
}
Having the script loop through the hundred of files, I was able to start it processing and go to bed. When I got up the next morning, I had an XML file for each table that I was able to import right into a MySQL database for my friend.
If you would like copies of the full scripts, feel free to email me.
Tuesday, June 26, 2012
Automating Database and Tables Size Checks
Working with SCCM, WSUS and other SQL DB driven applications, it seems like every once in a while you find that the database has grown out of control. Whenever this happens, obviously we have to quickly determine why it is so big, which means that we have to figure out what part of the database is growing and eating up all of that space. The sp_spaceused stored procedure is an easy and quick way to get database and database object sizes.
To get the database size, we can simply execute:
exec sp_spaceused
This tells us how big the database is, and breaks it down into data, reserved space, index size, and unused space. As sweet as that is, at this point we already know that the db is big, but we need to figure out why. Again, we can use the sp_spaceused stored procedure to check specific tables that we know may be problematic. For instance, if your WSUS SUSDB database is out of control, you could check the size of the tbEventInstance table by firing off:
exec sp_spaceused 'tbEventInstance'
This is great if you have a pretty good idea about which table is causing problems or if your dealing with a database that only has a couple of tables, but in systems like SCCM or WSUS, there could be any number of tables causing the problem. Executing that command against each table would take far too long. We can, however, use the sp_msForEachTable stored procedure to execute it against all tables at once:
exec sp_msForEachTable 'exec sp_spaceused [?]'
This gets us the size of each table, which is what we want. The problem is that we get a different result for each execution, that looks something like this:
 This is a good start, because now we just have to scan the list, but we can't sort this, so its still a manual process of looking through all of the output to find the problem. In a system like SCCM with a massive number of tables, this could still take a very long time.
This is a good start, because now we just have to scan the list, but we can't sort this, so its still a manual process of looking through all of the output to find the problem. In a system like SCCM with a massive number of tables, this could still take a very long time.
From here we can solve that problem by adding some SQL to create a temp table, dump the results of the command into that table, and then display the sorted contents of that table.
declare @tablesize table (
[name] nvarchar(256),
[rows] varchar(18),
reserved varchar(18),
data varchar(18),
index_size varchar(18),
unused varchar(18)
)
insert @tablesize exec sp_msForEachTable 'exec sp_spaceused [?]'
select * from @tablesize order by data desc
Now we have exactly what we want, with the largest tables right at the top!
This is much improved, but if we wanted to take it a step further, we could actually use PowerShell to run this query on a regular schedule and alert us if a table grows over a certain threshold. PowerShell makes it easy to grab the results of our exec sp_msForEachTable 'exec sp_spaceused [?]' and put it into a data set.
$SQLQuery = "exec sp_msForEachTable 'exec sp_spaceused [?]'"
$Conn = New-Object System.Data.SqlClient.SqlConnection
$Conn.ConnectionString = "Server = mydbserver; Database = MyDB; Integrated Security = True"
$SqlCmd = New-Object System.Data.SqlClient.SqlCommand
$SqlCmd.CommandText = $SqlQuery
$SqlCmd.Connection = $Conn
$SqlAdapter = New-Object System.Data.SqlClient.SqlDataAdapter
$SqlAdapter.SelectCommand = $SqlCmd
$DataSet = New-Object System.Data.DataSet
[void]$SqlAdapter.Fill($DataSet)
$Conn.Close()
$DataSet.Tables
Now you can loop through the $DataSer.Tables, check for a desired threshold, and execute actions if certain conditions are met. Then you will not only know that the database is growing rapidly before anyone notices, but you'll have the offending table identified so that you can go right to work on solving the problem. That certainly beats wasting time trying to identify the problem after people are complaining about application performance!
To get the database size, we can simply execute:
exec sp_spaceused
This tells us how big the database is, and breaks it down into data, reserved space, index size, and unused space. As sweet as that is, at this point we already know that the db is big, but we need to figure out why. Again, we can use the sp_spaceused stored procedure to check specific tables that we know may be problematic. For instance, if your WSUS SUSDB database is out of control, you could check the size of the tbEventInstance table by firing off:
exec sp_spaceused 'tbEventInstance'
This is great if you have a pretty good idea about which table is causing problems or if your dealing with a database that only has a couple of tables, but in systems like SCCM or WSUS, there could be any number of tables causing the problem. Executing that command against each table would take far too long. We can, however, use the sp_msForEachTable stored procedure to execute it against all tables at once:
exec sp_msForEachTable 'exec sp_spaceused [?]'
This gets us the size of each table, which is what we want. The problem is that we get a different result for each execution, that looks something like this:
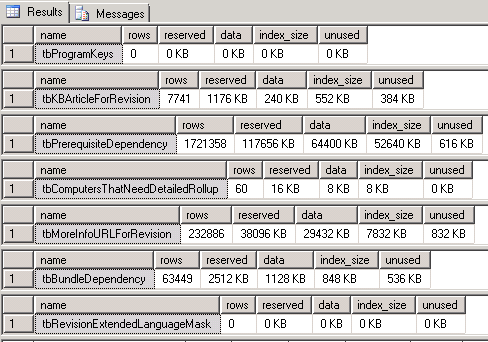
From here we can solve that problem by adding some SQL to create a temp table, dump the results of the command into that table, and then display the sorted contents of that table.
declare @tablesize table (
[name] nvarchar(256),
[rows] varchar(18),
reserved varchar(18),
data varchar(18),
index_size varchar(18),
unused varchar(18)
)
insert @tablesize exec sp_msForEachTable 'exec sp_spaceused [?]'
select * from @tablesize order by data desc
Now we have exactly what we want, with the largest tables right at the top!
This is much improved, but if we wanted to take it a step further, we could actually use PowerShell to run this query on a regular schedule and alert us if a table grows over a certain threshold. PowerShell makes it easy to grab the results of our exec sp_msForEachTable 'exec sp_spaceused [?]' and put it into a data set.
$SQLQuery = "exec sp_msForEachTable 'exec sp_spaceused [?]'"
$Conn = New-Object System.Data.SqlClient.SqlConnection
$Conn.ConnectionString = "Server = mydbserver; Database = MyDB; Integrated Security = True"
$SqlCmd = New-Object System.Data.SqlClient.SqlCommand
$SqlCmd.CommandText = $SqlQuery
$SqlCmd.Connection = $Conn
$SqlAdapter = New-Object System.Data.SqlClient.SqlDataAdapter
$SqlAdapter.SelectCommand = $SqlCmd
$DataSet = New-Object System.Data.DataSet
[void]$SqlAdapter.Fill($DataSet)
$Conn.Close()
$DataSet.Tables
Now you can loop through the $DataSer.Tables, check for a desired threshold, and execute actions if certain conditions are met. Then you will not only know that the database is growing rapidly before anyone notices, but you'll have the offending table identified so that you can go right to work on solving the problem. That certainly beats wasting time trying to identify the problem after people are complaining about application performance!
Subscribe to:
Posts (Atom)